
Introduction
In the realm of artificial intelligence, parameters serve as the fundamental building blocks that determine how AI models make decisions and predictions. Parameters primarily consist of the weights assigned to the connections between the small processing units called neurons, forming a vast interconnected network where each connection’s strength represents a critical parameter.
What Are AI Parameters?
Parameters in AI are the variables that the model learns during training. They are the internal variables that the model uses to make predictions or decisions. In a neural network, the parameters include the weights and biases of the neurons.
Think of AI parameters as ‘knobs and dials’ that an AI model learns to adjust during training. They’re like the ingredients in a recipe that determine the final flavor of the dish. More technically, parameters are internal variables that the model adjusts during training to improve its performance.
The Core Components of AI Parameters
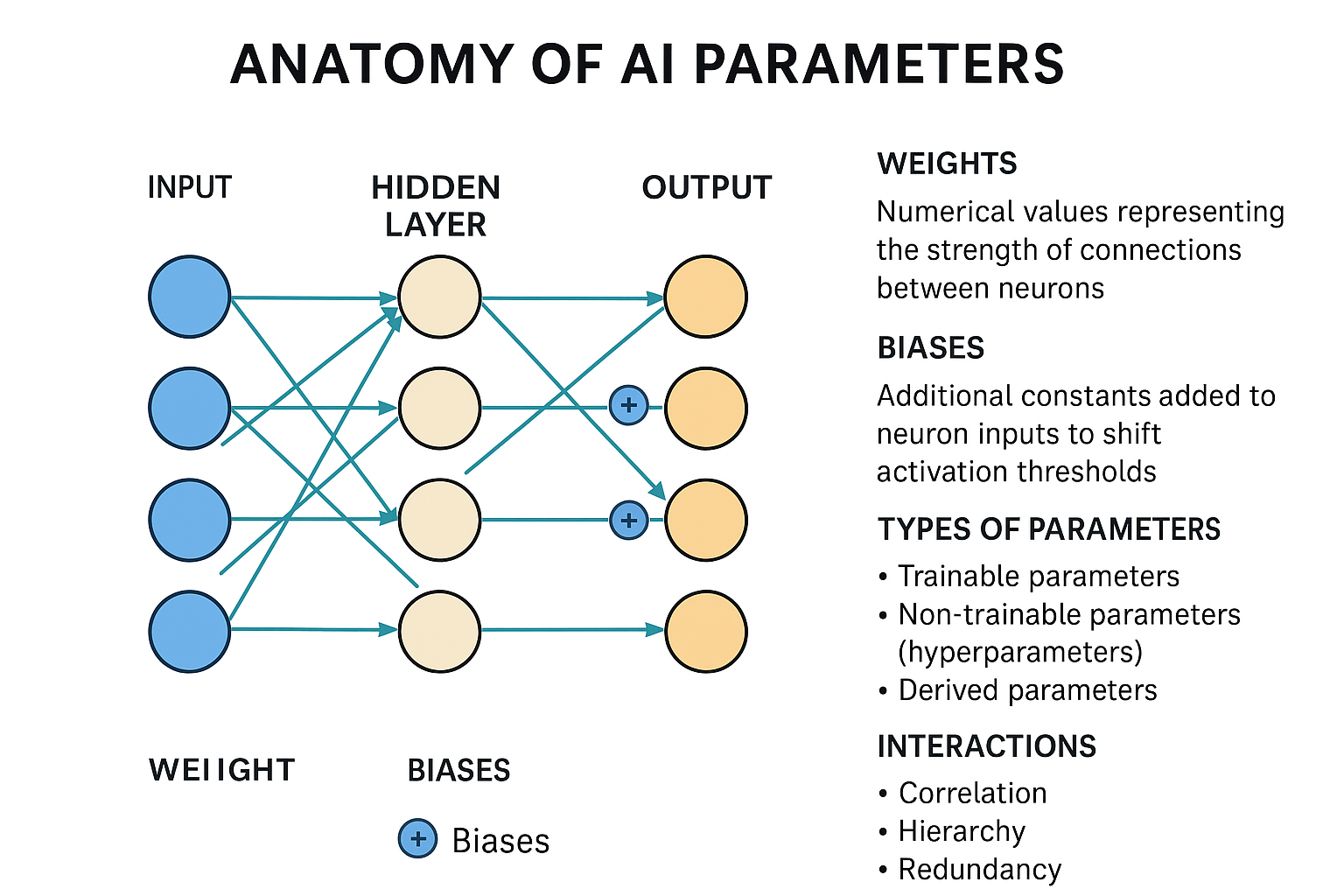
1. Weights
Weights represent the cornerstone of neural network parameters. Weights determine the strength of connections between neurons in different layers. Each connection between two neurons has an associated weight, which scales the input signal from one neuron to the next.
Key characteristics of weights:
- They control signal strength between neurons
- A weight decides how much influence the input will have on the output
- Weights are learned and adjusted during the training process
- They can be positive (excitatory) or negative (inhibitory)
2. Biases
Biases are constants added to the weighted sum of inputs before applying the activation function. The bias, since it is added to the whole expression, will move the function in the dimensional plane.
Functions of biases:
- Provide flexibility in shifting the activation function
- Allow neurons to activate even when all inputs are zero
- Help the model fit data that doesn’t pass through the origin
- Biases, which are constant, add an additional degree of freedom to the model
3. Parameter Calculation
The number of internal parameters in a neural network is total number of weights + the total number of biases. The total number of weights equals the sum of the products of each pair of adjacent layers. The total number of biases is equal to the number of hidden neurons + the number of output neurons.
Example calculation: There are 4 parameters used to calculate each of the 4 node values in the hidden layer—3 weights (one for each input value) and a bias—which sums to 16 parameters. Then there are 5 parameters used to calculate the output value: 4 weights (one for each node in the hidden layer) and a bias.
The Learning Process: Forward and Backward Propagation
Forward Propagation
The weights and biases develop how a neural network propels data flow forward through the network; this is called forward propagation. During this phase:
- Input data flows through the network
- Each neuron applies its weights to incoming signals
- Biases are added to the weighted sums
- Activation functions transform the results
- Outputs are generated for the next layer
Backward Propagation
Once forward propagation is completed, the neural network will then refine connections using the errors that emerged in forward propagation. Then, the flow will reverse to go through layers and identify nodes and connections that require adjusting; this is referred to as backward propagation.
Parameters vs. Hyperparameters
It’s crucial to distinguish between parameters and hyperparameters:
Parameters:
- Learned automatically during training
- Internal to the model
- Include weights and biases
- Determine the model’s predictions
Hyperparameters: Hyperparameters are parameters whose values control the learning process and determine the values of model parameters that a learning algorithm ends up learning. Examples include:
- Learning rate
- Number of layers
- Number of neurons per layer
- Batch size
- Number of training epochs
The Role of Parameters in Modern AI
Scale and Complexity
AI parameters — the variables used to train and tweak LLMs and other machine learning models — have played a crucial role in the evolution of generative AI. More parameters have enabled the ability of new generative AI apps like ChatGPT to produce human-like content.
Impact on Performance
For anyone exploring AI services, knowing how parameters affect performance can help them build or choose the right models. The number and quality of parameters directly influence:
- Model accuracy
- Generalization capability
- Computational requirements
- Training time and resources
Parameter Optimization Challenges
Overfitting and Regularization
Applications whose goal is to create a system that generalizes well to unseen examples, face the possibility of over-training. This arises in convoluted or over-specified systems when the network capacity significantly exceeds the needed free parameters.
Solutions include:
- Cross-validation techniques
- Regularization methods
- Dropout layers
- Early stopping
- Parameter sharing
Initialization and Training
Proper parameter initialization is critical for successful training:
- Random initialization prevents symmetry breaking
- Xavier/Glorot initialization maintains activation variance
- He initialization works well with ReLU activations
- Proper initialization prevents vanishing/exploding gradients
Mathematical Foundation
The basic neuron computation can be expressed as:
output = f(Σ(wi × xi) + b)Where:
- wi = weights for input i
- xi = input values
- b = bias term
- f = activation function
A single layer neural network computing a function Y =f(X,W) + (b1+ b2+ ….bn), where W is a weight matrix.
Modern Parameter Architectures
Attention Mechanisms
Modern architectures like Transformers introduce additional parameter types:
- Query, Key, Value matrices in attention layers
- Position embeddings
- Layer normalization parameters
Convolutional Networks
CNNs have specialized parameters:
- Convolutional kernels/filters
- Pooling parameters
- Stride and padding configurations
Recurrent Networks
RNNs and LSTMs include:
- Hidden state parameters
- Gate parameters (forget, input, output gates)
- Cell state parameters
Practical Implications
Model Size and Deployment
- Larger parameter counts require more memory
- Inference speed decreases with parameter count
- Mobile deployment requires parameter compression
- Edge computing demands efficient parameter usage
Training Considerations
- More parameters need more training data
- Computational costs scale with parameter count
- Distributed training becomes necessary for large models
- Memory management becomes critical
Future Directions
Parameter Efficiency
Research focuses on:
- Parameter sharing techniques
- Low-rank approximations
- Pruning and quantization
- Knowledge distillation
- Sparse parameter representations
Adaptive Parameters
Emerging concepts include:
- Dynamic parameter allocation
- Context-dependent parameters
- Meta-learning for parameter optimization
- Neural architecture search
Conclusion
AI parameters form the fundamental architecture of intelligent systems, serving as the learned knowledge that enables machines to make predictions and decisions. Understanding their anatomy—from basic weights and biases to complex attention mechanisms—is crucial for anyone working with modern AI systems. As models continue to grow in size and complexity, the efficient management and optimization of these parameters will remain a central challenge in artificial intelligence development.
The evolution from simple perceptrons with handful of parameters to modern language models with hundreds of billions of parameters represents one of the most significant advances in computational intelligence, with each parameter contributing to the model’s ability to understand and generate human-like responses.

Be First to Comment