
Introduction
Artificial intelligence (AI) and the graphics processing units (GPUs) that power it are redefining what clouds and data centres do, how they’re built, and why they matter. Once a niche for graphics and batch scientific computing, GPUs are now the workhorse for modern machine learning (ML) training and inference. Combined with software innovations and changing workloads, AI+GPU is reshaping every layer of the cloud and data-centre stack — from chips and racks to power, cooling, networking, and business models. This essay explains the technical drivers, architectural implications, operational impacts, and strategic opportunities that AI and GPUs bring to future cloud research and data-centre design.
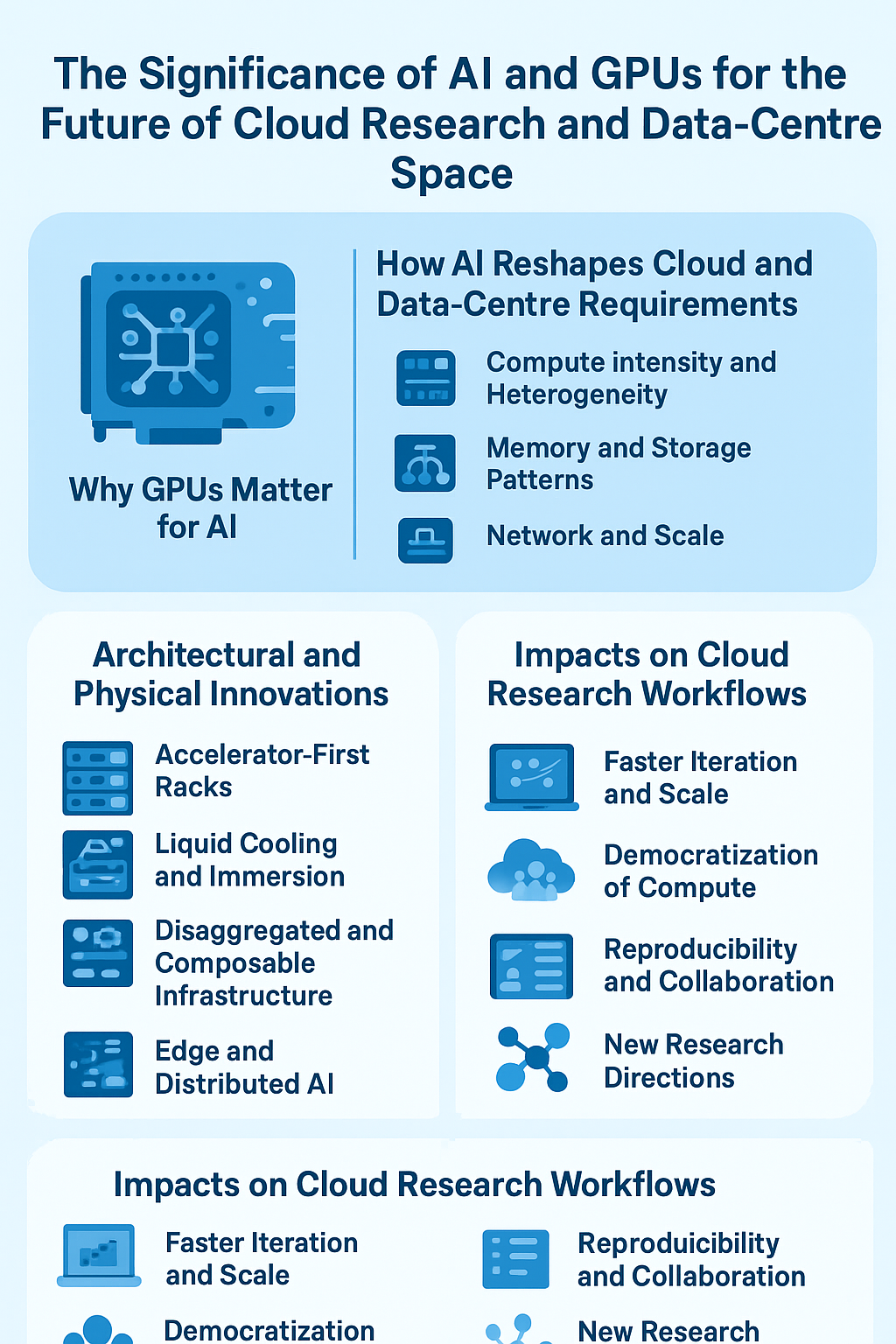
Why GPUs matter for AI
GPUs are specialized processors designed for highly parallel computation. Their architecture — thousands of simple cores, wide memory buses, and abundant matrix-math acceleration — matches the needs of AI workloads, especially deep learning:
- Massive parallelism: Neural-network operations (matrix multiplications, convolutions) split naturally across many cores.
- High memory bandwidth: Large models require moving and processing huge tensors quickly; GPUs reduce time spent waiting on memory.
- Dedicated accelerators: Modern GPUs include tensor cores, sparse compute units, and other features optimized for ML primitives.
- Software ecosystem: Frameworks (PyTorch, TensorFlow, CUDA, ROCm) and libraries exploit GPU hardware, accelerating developer productivity.
For cloud research — where researchers iterate on model architectures, hyperparameters, and large datasets — GPUs dramatically shorten experimentation cycles, enabling faster innovation.
How AI reshapes cloud and data-centre requirements
AI workloads differ from traditional enterprise or web workloads in predictable ways, and these differences drive changes in infrastructure:
- Compute intensity and heterogeneity
- Training large models demands sustained, high-density compute; inference often needs low-latency, high-throughput serving.
- Heterogeneous environments (GPUs, TPUs, FPGAs, NPUs) become standard. Cloud providers offer instance types optimized for both training and inference.
- Memory and storage patterns
- Datasets and models have ballooned: distributed storage (object stores, high-IOPS NVMe), tiered caching, and memory-centric architectures (disaggregated memory) are necessary.
- Model checkpoints and dataset versioning create heavy storage throughput and metadata load.
- Network and scale
- Distributed training uses heavy east-west traffic across nodes; high-bandwidth, low-latency fabrics (HDR InfiniBand, Ethernet at 100/200/400 Gbps) and advanced collective communication libraries are critical.
- Rack and pod designs must minimize hops and latency for synchronous training.
- Power and cooling
- GPU racks consume far more power and generate more heat per rack than CPU-only deployments. This raises constraints on power distribution and demands advanced cooling (liquid cooling, immersion) and more aggressive PUE strategies.
- Operational complexity
- Resource scheduling for heterogeneous accelerators, multi-tenant isolation, and cost-effective GPU utilization require new orchestration tools and smarter schedulers.
- Observability for ML pipelines (model metrics, data lineage, drift detection) becomes an operational priority.
Architectural and physical innovations
AI’s demands push data-centre design in several concrete directions:
- Accelerator-first racks: Racks built specifically for high accelerator density with power and cooling provisions that exceed traditional norms.
- Liquid cooling and immersion: As air cooling reaches limits, liquid cooling enables higher power densities and energy efficiency for GPU farms.
- Disaggregated and composable infrastructure: Separating compute, memory, storage, and accelerators into composable pools lets cloud operators allocate resources more efficiently to ephemeral ML jobs.
- Edge and distributed AI: Inference and some ML workloads move closer to data sources (edge data centres, on-prem micro-data centres) for latency, privacy, and bandwidth savings.
- Specialized network fabrics: Topologies optimized for all-reduce and collective ops reduce training time and improve scaling efficiency.
Impacts on cloud research workflows
For researchers and research institutions, the GPU-driven cloud enables new modes of work:
- Faster iteration and scale: Training times drop from days to hours, enabling more experiments and larger model families.
- Democratization of compute: Cloud GPU instances lower the barrier to entry for institutions that cannot afford on-prem GPU clusters.
- Reproducibility and collaboration: Managed ML platforms, experiment tracking, and dataset versioning in the cloud improve reproducibility across distributed teams.
- New research directions: Access to large compute encourages work on scaling laws, multimodal models, reinforcement learning at scale, and privacy-preserving ML.
Economic and business model shifts
The presence of AI and GPU needs changes how cloud providers and customers transact:
- Value-based pricing: Beyond raw hours, pricing can include inference throughput, model latency SLAs, or training-job completion guarantees.
- Spot and burst models: Efficient utilization strategies — spot GPUs for non-urgent training, reserved capacity for enterprise inference — emerge.
- Hardware lifecycle and second-use markets: Accelerators age, but can be repurposed for less demanding tasks; resale and lifecycle management become relevant.
Energy, sustainability, and ethics
With rising power demand, data centres must balance AI progress with sustainability:
- Efficiency improvements: PUE, advanced cooling, and specialized accelerator designs are prerequisites to limit carbon footprint.
- Renewables and load shaping: Timing flexible workloads (like large training runs) to coincide with renewable supply or using grid services lowers emissions.
- Ethical considerations: Model scale brings social risks (misuse, bias, environmental impact). Data-centre operators and researchers should include governance, transparency, and auditability in AI workflows.
Security, privacy, and compliance
AI workloads introduce unique security challenges:
- Model and data confidentiality: Model weights and training data can be highly sensitive; hardware-level isolation, encryption at rest/in transit, and confidential computing help mitigate risk.
- Adversarial and poisoning threats: Data provenance and robust validation pipelines become part of secure operations.
- Regulatory compliance: Data residency and privacy laws affect where training and inference can run — making hybrid and multi-region architectures important.
Research and innovation opportunities
AI+GPU in cloud and data centres open many research frontiers:
- Systems research: Scheduling algorithms for heterogeneous accelerators, efficient distributed training algorithms, and fault-tolerant large-scale ML systems.
- Hardware/software co-design: Tight integration between ML model designs and accelerator features (sparsity, quantization) to maximize performance and efficiency.
- Energy-aware ML: Models and training regimes that trade off accuracy for compute/energy cost, and automatic tuning systems that optimize for carbon or cost.
- Edge/continuum computing: New paradigms for training and inference across device–edge–cloud hierarchies.
Practical recommendations for stakeholders
- Cloud providers: Invest in accelerator diversity, advanced cooling, high-bandwidth networking, and ML-specific orchestration and observability tools.
- Enterprises & researchers: Adopt hybrid strategies: leverage cloud GPUs for scale and edge/on-prem for latency/privacy-critical inference. Use experiment tracking and dataset versioning.
- Policy makers & operators: Mandate transparency for high-impact models, incentivize energy-efficient data-centre design, and support workforce training for AI infrastructure management.
Conclusion
AI and GPUs are not merely another workload — they are a transformational force altering cloud architectures, data-centre engineering, operations, economics, and research agendas. They demand co-evolution across hardware, software, facilities, and governance. The winners will be organizations and researchers that treat AI infrastructure as a first-class design problem: building energy-efficient, secure, and flexible platforms that let models scale responsibly while keeping cost and sustainability in check. The future data-centre is an AI-native ecosystem — and mastering that ecosystem will define the next decade of cloud research and industry innovation.



Be First to Comment