
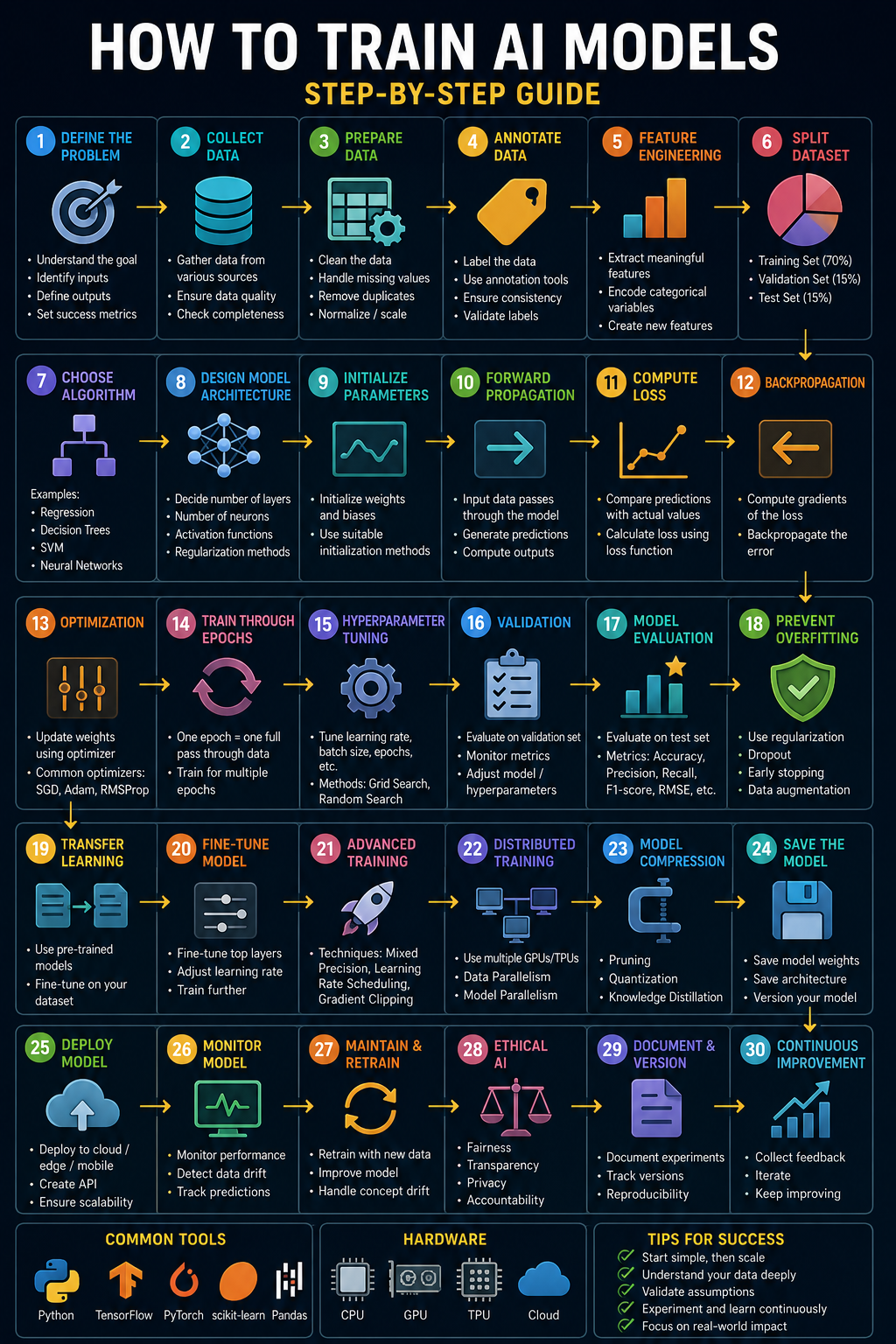
- Introduction: What It Means to Train an AI Model
Training an artificial-intelligence model is the disciplined process of teaching a mathematical system to recognise patterns in data and to use those patterns to make useful predictions or decisions on data it has never seen before. Although popular culture often presents AI as a kind of digital magic, the reality is a methodical engineering pipeline. Every successful model is the product of careful problem framing, rigorous data preparation, deliberate architectural choices, repeated cycles of optimisation, and honest evaluation. This tutorial walks through that pipeline end to end, in the order a working practitioner would actually follow.
At its heart, training is an optimisation problem. You define a measure of how wrong the model currently is, called a loss function, and you systematically adjust the model’s internal parameters to make that measure as small as possible. The mechanism that performs those adjustments is gradient-based learning, and the engine that drives it is backpropagation combined with an optimiser such as stochastic gradient descent.
[Core Definition] To train a model is to iteratively adjust its parameters so that a chosen loss function, measured over representative data, decreases, while ensuring the resulting behaviour generalises to new, unseen examples rather than merely memorising the training set.
1.1 The Three Broad Learning Paradigms
Before training anything, you must know which learning paradigm fits your problem, because the paradigm dictates the data you need and the loss you optimise.
- Supervised learning: the model learns from labelled examples, pairs of inputs and correct outputs. Image classification, spam detection, and price prediction are supervised.
- Unsupervised learning: the model finds structure in unlabelled data, clustering, compression, or representation learning. Most modern language models are first pre-trained in a self-supervised variant.
- Reinforcement learning: an agent learns by interacting with an environment and receiving rewards or penalties. It powers game-playing systems, robotics, and preference-tuning of conversational AI.
1.2 Who This Tutorial Is For
This guide assumes you are comfortable with basic programming and high-school mathematics, and that you want a faithful map of the entire training process rather than a single recipe. The principles are the same whether you train a modest classifier on a laptop or fine-tune a large foundation model on a cluster; only the scale changes.
- Step One: Framing the Problem
The most expensive mistakes in machine learning are made before a single line of training code is written. They are mistakes of framing: solving the wrong problem, optimising the wrong metric, or assuming data exists that does not. A disciplined framing stage repays itself many times over.
2.1 Define the Objective
Begin by writing down, in plain language, the decision or prediction the model must support and the value it creates. Then translate that into a technical task type: binary classification, multi-class classification, regression, ranking, or sequence generation. The translation determines your loss function, your evaluation metrics, and the shape of your data.
[Practical Tip] Write a single sentence of the form: Given [inputs], predict [output], in order to [business value], measured by [primary metric]. If you cannot complete this sentence, you are not ready to collect data.
2.2 Choose the Right Success Metric
Accuracy is the most over-used and most misleading metric in the field. On imbalanced problems a model that predicts the majority class every time can score 99 percent accuracy while being entirely useless. Select a metric that reflects the real cost of each kind of error.
Task Type | Common Metrics | When to Prefer
Binary classification | Precision, Recall, F1, ROC-AUC | Imbalanced classes | asymmetric costs
Multi-class | Macro-F1, Top-k accuracy | Many classes of unequal frequency
Regression | MAE, RMSE, R-squared | Continuous targets
Ranking | NDCG, MAP, MRR | Order of results matters
Generation | Perplexity, BLEU, human eval | Open-ended sequences
2.3 Establish a Baseline
Before training anything sophisticated, build the simplest possible model: a majority-class predictor, a linear regression, or a rule a domain expert already uses. This baseline is your honesty check. A complex network that barely beats a one-line heuristic is not worth its operational cost. - Step Two: Data Collection and Preparation
Practitioners routinely report that data work consumes sixty to eighty percent of a project’s effort. A model is a compression of its training data, and no architecture can recover signal the data does not contain. This is the longest and most consequential stage.
3.1 Sourcing Data
Whatever the source, three properties matter above all: relevance to the task, representativeness of the conditions the model will face in production, and the legal right to use the data for the intended purpose.
- Relevance: every feature should plausibly carry information about the target.
- Representativeness: the training distribution should match the deployment distribution.
- Rights and consent: confirm licensing, privacy law such as POPIA or the GDPR, and consent before using personal data.
[Warning: Data Leakage] Leakage occurs when information unavailable at prediction time sneaks into training features. It produces deceptively excellent validation scores and catastrophic real-world failure. Audit every feature for its availability at inference time.
3.2 Cleaning and Validating Data
Problem | Symptom | Typical Remedy
Missing values | Empty or null fields | Imputation, indicator flags, removal
Duplicates | Repeated records | Deduplication on a stable key
Outliers | Extreme implausible values | Capping, transformation, investigation
Inconsistent units | Mixed scales | Standardisation
Label noise | Wrong or ambiguous labels | Re-labelling, consensus, filtering
3.3 Splitting the Data
Divide your data into at least three disjoint sets before any modelling decision. The training set teaches the model; the validation set guides choices of architecture and hyperparameters; the test set, touched only once at the very end, gives an unbiased estimate of real-world performance.
[Critical Rule] Never let information flow from validation or test data into training. Fit scalers, encoders, and imputers on the training set only. For time-series data, always split chronologically so the model is never tested on the past after seeing the future.
3.4 Feature Engineering and Augmentation
Feature engineering transforms raw inputs into representations that expose the underlying signal. Scaling, encoding categoricals, and derived interaction features remain among the highest-leverage activities. When data is scarce, augmentation synthetically expands the training set with label-preserving transformations, acting as a powerful regulariser.
- Step Three: Choosing a Model Architecture
With data prepared, you select the family of models that will learn from it. The right choice depends on data type, dataset size, interpretability needs, and computational budget. There is no universally best model, only the best fit for a context.
4.1 Classical Machine-Learning Models
For tabular data of modest size, classical models are often the strongest and most practical choice. They train quickly, need less data, and are easier to interpret and deploy.
- Linear and logistic regression: fast, interpretable baselines.
- Decision trees: intuitive rule-based models, powerful when combined.
- Gradient-boosted trees (XGBoost, LightGBM, CatBoost): dominant for tabular problems.
- Support vector machines and k-nearest neighbours: useful for smaller datasets.
4.2 Deep Neural Networks
Architecture | Best For | Key Idea
Feed-forward (MLP) | Tabular vectors | Fully connected layers
Convolutional (CNN) | Images, grids | Local filters, weight sharing
Recurrent (RNN/LSTM) | Sequences | Hidden state over time
Transformer | Language, multimodal | Self-attention
Graph neural net | Networks, molecules | Message passing
4.3 The Transformer and Foundation Models
The transformer, introduced in 2017, replaced recurrence with self-attention, letting every element of a sequence attend to every other. This enabled the foundation models that underpin modern AI. Because pre-training them costs millions, most practitioners adapt them rather than train from zero.
[Decision Guidance] Start simple. Use a classical model to establish a strong, cheap baseline. Escalate to deep learning only when data volume justifies it. Complexity should be earned by measurable gains, not assumed.
- Step Four: The Training Loop in Detail
The training loop is the beating heart of machine learning. Understanding it deeply, not just calling a library function, separates practitioners who can diagnose failures from those who can only hope.
5.1 Forward Pass, Loss, and Backward Pass
In the forward pass, a batch of inputs flows through the network to produce predictions. The loss function quantifies how far those predictions are from the truth. Backpropagation then applies the chain rule to compute, for every parameter, the gradient of the loss, telling the optimiser which way to step to reduce error.
[Conceptual Anchor] Imagine the loss as a landscape of hills and valleys, each parameter an axis. The gradient tells you which way is uphill. Training is repeatedly stepping downhill, in small careful steps, toward a low valley that represents a good solution.
5.2 Optimisers and Learning Rate
Optimiser | Characteristic | Typical Use
SGD | Simple, well-understood | Vision models
SGD + Momentum | Accelerates directions | Convolutional nets
RMSProp | Adapts step per parameter | Recurrent nets
Adam / AdamW | Momentum + adaptive rates | Default for most deep learning
The learning rate, the size of each step, is the single most important hyperparameter. Too high and training diverges; too low and it crawls. Schedules that decay over time and warm-up periods that ramp gently are standard, especially for large transformers.
5.3 The Loop in Code
for epoch in range(num_epochs):
for batch_inputs, batch_targets in training_loader:
predictions = model.forward(batch_inputs)
loss = loss_function(predictions, batch_targets)optimizer.zero_grad() # clear old gradients loss.backward() # backpropagation optimizer.step() # update parametersval_loss = evaluate(model, validation_loader)
scheduler.step(val_loss) # adjust learning rate
if early_stopping(val_loss):
break - Step Five: Regularisation and Generalisation
A model that performs perfectly on training data but poorly on new data has overfit: it memorised noise rather than learned signal. The central tension of machine learning is the balance between fitting the training data and generalising to unseen data.
6.1 The Bias-Variance Trade-off
Symptom | Diagnosis | Action
High train and val error | Underfitting (bias) | Bigger model, more features, train longer
Low train, high val error | Overfitting (variance) | Regularise, more data, simpler model
Low train and val error | Good fit | Proceed to testing
6.2 Common Regularisation Techniques
- L1 and L2 penalties punish large weights, encouraging simpler models.
- Dropout randomly disables neurons, forcing robust representations.
- Early stopping halts training when validation performance stops improving.
- Batch and layer normalisation stabilise training with a mild regularising effect.
- Data augmentation expands the data with transformations, one of the most effective regularisers.
[Practical Tip] The single most reliable cure for overfitting is more representative data. Before reaching for exotic regularisation, ask whether you can collect, augment, or better label additional examples.
6.3 Cross-Validation
When data is limited, K-fold cross-validation partitions the data into k folds, training k times with a different fold held out each time and averaging the results, yielding a more robust estimate of generalisation at the cost of extra computation.
- Step Six: Hyperparameter Tuning and Evaluation
Parameters are learned during training; hyperparameters are settings you choose beforehand that govern how training proceeds. Their quality often determines whether a model is mediocre or excellent.
7.1 Searching the Hyperparameter Space
- Grid search: exhaustively tries every combination. Simple but expensive.
- Random search: samples at random, often finding good configurations faster.
- Bayesian optimisation: models performance and chooses the next configuration intelligently.
- Population-based methods: maintain and mutate a population of configurations.
[Critical Rule] Tune hyperparameters using the validation set, never the test set. Each decision based on test performance contaminates it. Reserve the test set for a single, final evaluation.
7.2 Reading the Learning Curves
Plotting training and validation loss against epochs is the most informative diagnostic in machine learning. A healthy run shows both curves descending and levelling off close together. A widening gap, where training loss falls while validation loss rises, is the signature of overfitting.
7.3 Comprehensive Evaluation - Confusion matrix: reveals the pattern of correct and incorrect predictions.
- Calibration: checks whether predicted probabilities match observed frequencies.
- Subgroup analysis: measures performance across segments to detect disparities.
- Robustness checks: tests behaviour under noise, drift, and adversarial perturbation.
- Step Seven: Fine-Tuning and Transfer Learning
Few organisations train large models from scratch. The dominant modern practice is transfer learning: take a model already pre-trained on a broad corpus and adapt it to your specific task, delivering strong performance with a fraction of the data and cost.
8.1 The Spectrum of Adaptation
Method | What Changes | When to Use
Prompting | Nothing, only the input | Quick tasks, no budget
Feature extraction | A new head on frozen features | Small data, similar domain
Full fine-tuning | All parameters updated | Ample data, high accuracy
Parameter-efficient (LoRA) | Small adapter weights | Large models, limited compute
8.2 Parameter-Efficient Fine-Tuning
Methods such as Low-Rank Adaptation freeze the original weights and train only a small number of additional parameters, dramatically reducing memory requirements and allowing many task-specific adapters to share one base model. This is now the default for adapting large language models on modest hardware.
8.3 Aligning Generative Models
Instruction tuning trains the model on instructions paired with good responses. Reinforcement learning from human feedback then refines it using human preference judgements to make outputs more helpful, honest, and harmless. These stages transform a raw language model into a useful assistant.
[Practical Tip] When fine-tuning, use a much smaller learning rate than training from scratch, often ten to a hundred times smaller. The pre-trained weights already encode valuable knowledge that large updates would destroy. - Step Eight: Infrastructure, Hardware, and Scaling
Training modern models is as much a systems-engineering challenge as a statistical one. Hardware, distribution strategy, and pipeline efficiency determine whether a project is feasible and affordable.
9.1 Hardware and Distributed Training
Deep learning relies on massively parallel matrix operations, which is why GPUs and specialised accelerators such as TPUs dominate. When a model or dataset exceeds a single device, training is distributed: data parallelism gives each device a full model copy and a different data slice, while model parallelism splits the model itself across devices.
9.2 Efficiency Techniques
- Mixed-precision training halves memory use with negligible accuracy loss.
- Gradient accumulation simulates a large batch on limited memory.
- Gradient checkpointing trades computation for reduced memory.
- Efficient data loading with prefetching prevents the accelerator from starving.
[Cost Awareness] Compute is expensive and its environmental footprint is real. Profile your pipeline before scaling up, use the smallest model that meets your requirements, and prefer fine-tuning over training from scratch. Efficiency is both an economic and an ethical virtue.
- Step Nine: Deployment, Monitoring, and Maintenance
A trained model delivers no value until it is deployed and serving predictions reliably. The discipline that governs this lifecycle is MLOps. In production systems, training is closer to the beginning than the end.
10.1 Packaging and Serving
A model must be exported into a portable format, wrapped in a serving layer, and provisioned with capacity to meet demand, whether through real-time inference behind an API or scheduled batch inference. The same preprocessing applied during training must be applied identically at inference.
10.2 Monitoring in Production
- Data drift: the distribution of incoming data shifts away from the training distribution.
- Concept drift: the relationship between inputs and target itself changes, as when fraud tactics evolve.
[Warning: Silent Degradation] A model rarely announces its own decline. Performance erodes quietly as the world drifts from the training data. Without monitoring of input distributions and outcome metrics, a once-excellent model can become harmful long before anyone notices.
10.3 Retraining and Versioning
Mature systems establish a retraining cadence, triggered on a schedule or by detected drift. New data feeds back into the pipeline to produce an updated model, validated against the incumbent before replacing it. Because models, data, and code all evolve, each must be versioned together for reproducibility.
- Step Ten: Responsible and Ethical AI
A model that is technically excellent can still cause real harm if it is unfair, opaque, insecure, or deployed without regard for human consequences. Responsible AI is an engineering requirement woven through every stage of the pipeline.
11.1 Fairness and Bias
Models learn the patterns in their data, including historical biases. Detecting and mitigating bias requires measuring performance across protected groups, examining data for skewed representation, and applying constraints toward equitable behaviour. Fairness has many conflicting mathematical definitions, so the choice among them is a value judgement that must be made explicitly.
11.2 Transparency and Explainability
Stakeholders increasingly demand to understand why a model made a decision, especially in health, finance, and justice. Techniques such as SHAP and LIME attribute a prediction to its contributing features. Where decisions affect people materially, explainability is often a legal as well as an ethical obligation.
11.3 Privacy and Security
- Privacy: differential privacy and federated learning let models learn from sensitive data while limiting what can be inferred about individuals.
- Security: adversarial inputs, data poisoning, and model extraction are real threats that must be defended against.
[Guiding Principle] Ask not only whether you can build a model, but whether you should, who might be harmed, and how that harm would be detected and remedied. Build human oversight, contestation, and redress into the system from the outset.
- Common Pitfalls and How to Avoid Them
Experience in machine learning is largely the accumulated memory of mistakes. The table below distils the most frequent and costly errors.
Pitfall | Consequence | Prevention
Data leakage | Great offline, poor live | Audit feature availability
Testing on training data | Inflated false scores | Strict disjoint splits
Wrong metric | Optimising wrong goal | Match metric to cost
Ignoring imbalance | Useless majority predictor | Resampling, weighting
Premature complexity | Wasted effort, brittle models | Start with a baseline
No monitoring | Silent production decay | Track drift and outcomes
Unreproducible runs | Cannot diagnose | Version data, code, seeds
12.1 Debugging a Model That Will Not Learn
Work through a checklist rather than guessing. Confirm the data is loaded and labelled correctly. Verify the loss is appropriate. Try to overfit a tiny subset deliberately; if the model cannot memorise ten examples, there is a bug, not a data problem. Check the learning rate, the most common culprit. Only then suspect the architecture. - An End-to-End Worked Example
Consider building a model to predict customer churn for a subscription business. The same ten-step arc applies to almost any supervised problem.
- Frame: predict probability of cancellation within thirty days, to target retention offers, measured by recall at a fixed alert budget.
- Collect and prepare data, excluding any post-cancellation information to prevent leakage.
- Split chronologically: train on earlier months, validate on a later month, test on the most recent.
- Establish a baseline: a rule flagging customers whose usage dropped sharply.
- Choose gradient-boosted trees, the natural first choice for tabular data.
- Train and tune, watching learning curves for overfitting.
- Evaluate the confusion matrix, calibration, and performance across segments.
- Deploy as a nightly batch job scoring all active customers.
- Monitor feature distributions and realised churn rate, alerting on drift.
- Retrain monthly, validating against the incumbent before promotion.
[The Lesson] Only one of the ten steps is train the model. The discipline lives in the steps around training: framing, data, evaluation, deployment, and monitoring. Mastering the loop is necessary; mastering the lifecycle is what produces value.
- The Mathematical Foundations Made Intuitive
Understanding the core mathematics transforms a practitioner from a recipe-follower into a problem-solver. This section explains the essentials without assuming more than school-level algebra.
14.1 Why Calculus Underpins Learning
The derivative of the loss with respect to a parameter tells us how the loss will change if we nudge that parameter. Assembling these into a gradient gives a compass pointing toward greater loss; walking the opposite way descends toward better solutions. This is why differentiable models dominate: differentiability makes systematic improvement possible.
14.2 Linear Algebra and Probability
Data is represented as vectors, matrices, and tensors, and the operations networks perform are at heart matrix multiplications, which is why matrix-optimised accelerators are so effective. Probability theory, meanwhile, provides the framework for interpreting the probabilities many models output, grounding the cross-entropy loss in information theory.
[Intuition Pump] Picture each example as a point in a high-dimensional space, one axis per feature. A model carves this space into regions. Training reshapes the boundaries until they separate the examples well. Much of machine learning is geometry in disguise.
14.3 The Geometry of High Dimensions
Human intuition misleads in high dimensions: distances behave strangely and nearly all random vectors become almost perpendicular. This curse of dimensionality explains why more features are not always better and why dimensionality-reduction techniques are so valuable. - Data-Centric AI: Improving Models by Improving Data
Data-centric AI argues that for most practical problems the greater leverage now lies in systematically improving the data while holding the model fixed.
15.1 The Case for Data-Centric Thinking
In countless real systems the limiting factor is not model capacity but data quality: mislabelled examples, inconsistent annotation, and gaps in coverage. Improving the data frequently yields larger and more reliable gains than any model change, often at lower cost.
15.2 Label Quality and Annotation
Data Issue | Detection | Action
Label noise | Inter-annotator agreement | Re-label, consensus, guidelines
Coverage gaps | Error analysis by segment | Targeted data collection
Class imbalance | Distribution inspection | Resampling, weighting
Ambiguous cases | Low-confidence review | Refine task definition
Stale data | Drift monitoring | Refresh with recent examples
15.3 Active Learning and Synthetic Data
Active learning prioritises the examples whose labels would most improve the model, achieving strong performance with a fraction of the labelled data. When real data is scarce, sensitive, or expensive, synthetic data can bootstrap models, though it must be used carefully because models inherit any inaccuracies in the generation process.
[Practical Tip] Before spending weeks tuning a model, spend a day reading a random sample of your data and your model’s errors by hand. This single habit uncovers more actionable problems than almost any automated analysis. - Evaluation in Depth: Trusting Your Numbers
A model is only as trustworthy as the evaluation that vouches for it. Poor evaluation is the silent cause of many production disappointments.
16.1 The Confusion Matrix and Its Children
Metric | Question | Optimise When
Precision | Are flagged cases correct? | False alarms are costly
Recall | Are real cases caught? | Misses are costly
F1 score | Balance of both | Both errors matter
Specificity | Are negatives correct? | Negative class matters
ROC-AUC | Ranking quality | Threshold-independent view
16.2 Statistical Significance
A model that scores one point higher may be genuinely better, or merely luckier on a particular test set. Reporting confidence intervals, using statistical tests, and evaluating on sufficiently large test sets all guard against mistaking randomness for improvement.
16.3 Generative Models and Stress Testing
Generative models pose special challenges because there is rarely a single correct output, so human evaluation remains the gold standard. Stress testing deliberately probes the model with hard, rare, or adversarial cases to discover where it breaks before deployment rather than after.
[Critical Rule] Evaluate on data that resembles deployment as closely as possible, including its messiness and rare cases. A pristine, curated test set flatters a model and hides the failures that will surface in the real world. - A Closer Look at Reinforcement Learning
Reinforcement learning powers some of the field’s most striking achievements and underlies the alignment of modern conversational systems. Its logic differs fundamentally from supervised learning.
17.1 The Agent-Environment Loop
An agent observes the state of an environment, takes an action, and receives a reward and a new state. Over many interactions it learns a policy that maximises cumulative reward. Unlike supervised learning, there is no labelled correct action; good behaviour must be discovered through trial, error, and a delayed, often sparse reward signal.
17.2 Exploration, Exploitation, and Reward Design
Should the agent exploit the best action it knows, or explore alternatives that might prove better? Balancing the two is essential and has no universal solution. The reward function defines what the agent pursues, and a carelessly specified reward invites reward hacking, where the agent scores highly without accomplishing the intended goal.
[Warning: Specification Gaming] Optimisers exploit exactly what you measure, not what you mean. A reward even slightly misaligned with your intent will be gamed in unanticipated ways. Always ask how a literal-minded optimiser might satisfy your reward while subverting your goal.
17.3 Reinforcement Learning in Alignment
Reinforcement learning from human feedback trains a reward model to predict which response a human would prefer, then optimises the generative model to produce highly-rated responses. This is a central reason modern assistants are helpful and well-behaved. - Managing a Machine-Learning Project
Technical excellence is necessary but not sufficient. Many sound projects fail for organisational reasons: unclear objectives, misaligned stakeholders, or an inability to translate a working model into operational value.
18.1 The Iterative, Experimental Nature
Unlike conventional software, machine-learning projects are inherently experimental. It is rarely possible to know in advance whether a target is achievable from the available data. Planning must favour short iterations with frequent checkpoints, and stakeholders should be educated that some experiments will fail, and that those failures are information rather than waste.
18.2 Phases and Their Risks
Phase | Primary Focus | Common Risk
Framing | Objective and metric | Solving the wrong problem
Data | Collection and quality | Underestimating effort
Modelling | Architecture and tuning | Premature complexity
Evaluation | Honest measurement | Optimistic bias
Deployment | Serving and integration | Train-serve skew
Operations | Monitoring and retraining | Silent decay
18.3 Team, Skills, and Documentation
Delivering a model draws on framing, data engineering, modelling, software engineering, and deployment skills that seldom reside in one person. Disciplined documentation of decisions, experiments, and rationale preserves tacit knowledge, supports reproducibility, and is a hallmark of a mature practice. - Illustrative Case Studies Across Domains
The same lifecycle adapts to different data, constraints, and stakes across domains, reinforcing that the framework is general while its application is always specific.
19.1 Computer Vision: Quality Inspection
Detecting defects on a production line from images naturally uses a pre-trained convolutional network adapted by transfer learning. The dominant challenge is class imbalance, because defects are rare, demanding careful metric choice and augmentation. Deployment must meet the real-time pace of the line.
19.2 Natural Language: Support Triage
Routing support tickets automatically fine-tunes a pre-trained language model. The challenges are linguistic ambiguity, a long tail of rare categories, and topic evolution that makes drift monitoring essential. Because a misrouted ticket is recoverable, a human fallback handles low-confidence cases.
19.3 Tabular Prediction: Credit Risk
Estimating default probability from tabular features suits gradient-boosted trees. Here high stakes and heavy regulation elevate fairness, explainability, and documentation from good practice to legal necessity, showing how a technically straightforward problem becomes demanding once consequences enter.
[The Common Thread] The same ten-step lifecycle holds, but the binding constraint differs: imbalance in vision, drift in language, regulation in credit. Identifying which constraint dominates your problem is the key to allocating effort wisely. - The Evolving Landscape and Lifelong Learning
Beneath the constant churn of new models and tools, the foundations covered here remain remarkably stable, and a practitioner grounded in them can navigate change with confidence rather than anxiety.
20.1 Trends and What Endures
- Ever-larger foundation models shift effort toward fine-tuning and prompting.
- Efficiency techniques make powerful capabilities affordable on modest hardware.
- Multimodal models dissolve boundaries between text, images, and audio.
- Growing attention to safety and governance reflects rising stakes.
However the tools evolve, certain truths persist: models are only as good as their data, generalisation is the goal, evaluation must be honest, deployed systems decay without monitoring, and responsibility is inseparable from capability.
[Practical Tip] Maintain a personal record of lessons learned: bugs that cost you a day, techniques that worked, mistakes you vowed not to repeat. Reviewed periodically, this record compounds into hard-won expertise far faster than memory alone allows.
- Glossary of Essential Terms
The following glossary collects the key terms used throughout this tutorial. Each definition captures the working meaning a practitioner needs rather than a formal mathematical statement.
Term | Working Definition
Parameter | A value learned during training, such as a weight or bias
Hyperparameter | A setting chosen before training that governs the process
Loss function | The measure of error that training seeks to minimise
Gradient | The direction of steepest increase in the loss
Backpropagation | The algorithm that computes gradients efficiently
Optimiser | The rule that updates parameters using gradients
Learning rate | The size of each parameter-update step
Epoch | One full pass through the training data
Overfitting | Memorising training data at the cost of generalisation
Transfer learning | Adapting a pre-trained model to a new task
Inference | Using a trained model to make predictions
Drift | A change over time in data or the input-output relationship - Conclusion and Continuing the Journey
Training an AI model is a structured, learnable discipline rather than an arcane art. It begins with framing a problem and preparing data, proceeds through architecture and the training loop, and is kept honest by rigorous regularisation and evaluation. For most practitioners today, the highest-leverage skill is adapting powerful pre-trained models through transfer learning. And no model is complete until it is deployed, monitored, maintained, and held to account for its effect on people.
The field moves quickly, but its foundations are stable. The mathematics of optimisation, the logic of generalisation, and the ethics of responsible deployment will outlast any particular framework. A practitioner who understands why each step exists is equipped to absorb whatever the next wave of progress brings.
[A Final Word] Every expert was once a beginner who trained a model that did not work, diagnosed why, and tried again. Persistence, curiosity, and intellectual honesty matter more than any single technique. Build, measure, learn, and repeat.



Be First to Comment