
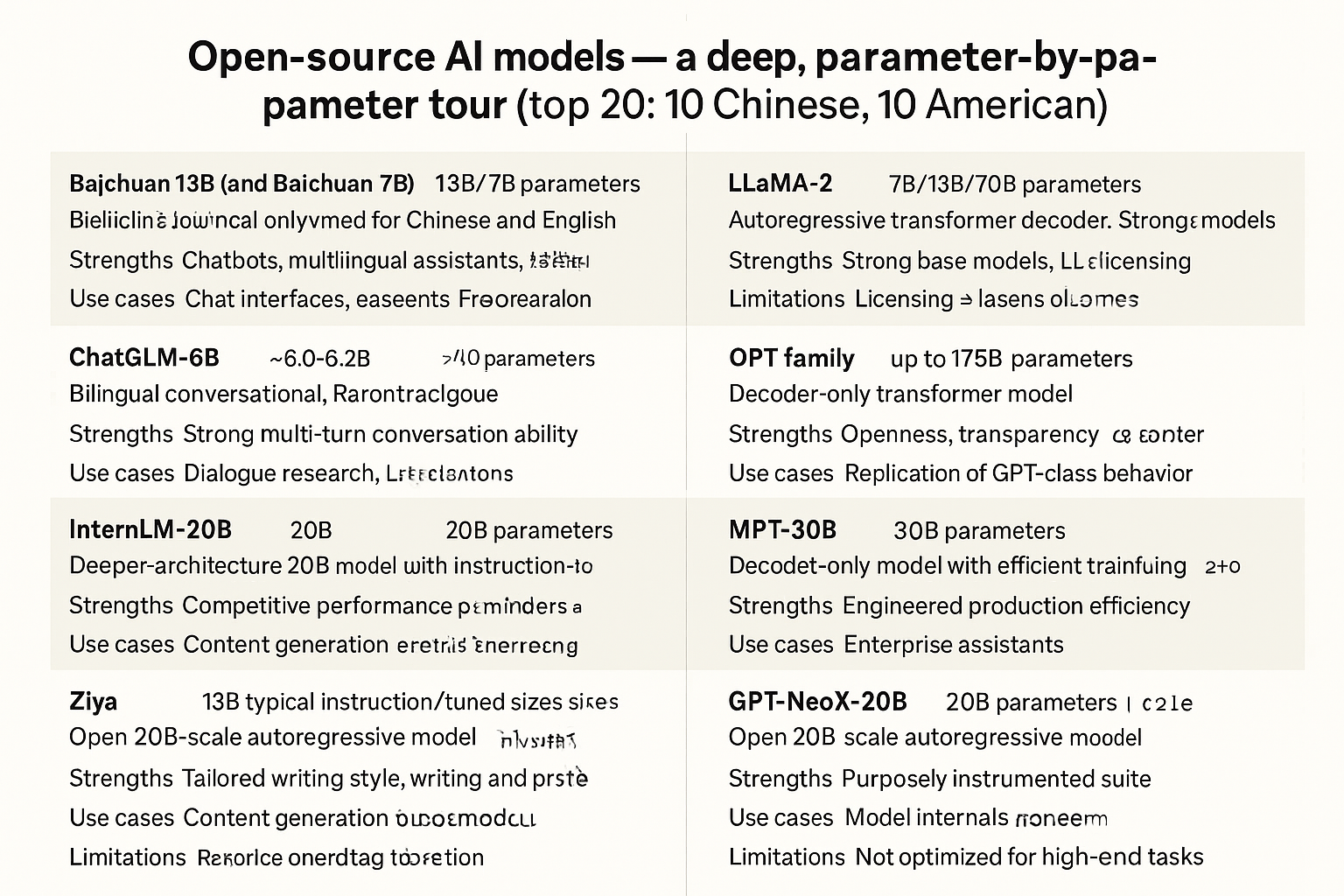
The open-source AI revolution has democratized access to cutting-edge artificial intelligence, enabling researchers, developers, and organizations worldwide to build upon foundational models without prohibitive costs. This article explores 20 leading open-source AI models—10 from China and 10 from the United States—examining their unique architectures, parameters, and contributions to the field.
American Open-Source AI Models
1. LLaMA 2 (Meta AI)
Meta’s LLaMA 2 represents a watershed moment in open-source language models. Released in July 2023, it comes in three parameter sizes: 7 billion, 13 billion, and 70 billion parameters.
Key Parameters:
- Architecture: Transformer-based decoder-only model
- Context Length: 4,096 tokens
- Training Data: 2 trillion tokens from publicly available sources
- Grouped-Query Attention (GQA): Implemented in the 70B model for improved inference efficiency
- Vocabulary Size: 32,000 tokens using byte-pair encoding
LLaMA 2’s architectural refinement over its predecessor includes enhanced attention mechanisms and more robust safety guardrails. The model employs pre-normalization using RMSNorm and uses the SwiGLU activation function, which improves performance over traditional ReLU variants.
2. Mistral 7B (Mistral AI)
Despite being founded by former Meta and Google DeepMind researchers, Mistral AI operates primarily from the US market. Their 7B model punches well above its weight class.
Key Parameters:
- Sliding Window Attention (SWA): 4,096-token window enabling effective 32k context handling
- Grouped-Query Attention: Reduces memory requirements during inference
- Rolling Buffer Cache: Limits cache size while maintaining performance
- Pre-fill and Chunking: Optimizes prompt processing
- Architecture: Decoder-only transformer with 32 layers
The sliding window attention mechanism is Mistral’s innovation—each layer attends to the previous 4,096 tokens, but information can propagate further through stacked layers, creating an effective receptive field exceeding 100k tokens.
3. Falcon 180B (Technology Innovation Institute – UAE/US Partnership)
Developed with significant US collaboration, Falcon 180B was trained on 3.5 trillion tokens, making it one of the most extensively trained open models.
Key Parameters:
- Parameters: 180 billion
- Architecture: Decoder-only with multi-query attention
- Context Length: 2,048 tokens
- Training Data: RefinedWeb dataset (heavily filtered web data)
- Unique Feature: Parallel attention and MLP processing
Falcon’s multi-query attention allows multiple queries to share key-value projections, dramatically reducing memory bandwidth requirements. The model also employs rotary positional embeddings (RoPE) for better length generalization.
4. StableLM (Stability AI)
Stability AI’s language model series includes versions from 3B to 65B parameters, designed for efficient deployment.
Key Parameters:
- Available Sizes: 3B, 7B, 12B, 65B
- Context Length: Up to 4,096 tokens
- Training Approach: Multi-stage training with increasing context lengths
- Architectural Innovation: Layer-wise learning rate decay
- Tokenizer: GPT-NeoX based (50,280 vocabulary)
StableLM implements progressive training, starting with shorter contexts and gradually expanding, which improves both efficiency and long-range coherence.
5. MPT (MosaicML)
MosaicML’s MPT (MosaicML Pretrained Transformer) series includes the notable MPT-7B and MPT-30B variants.
Key Parameters:
- Context Length: Up to 65,536 tokens (MPT-7B-StoryWriter)
- Architecture: Modified transformer with ALiBi positional encodings
- Flash Attention: Integrated for efficiency
- No Position Embeddings: Uses ALiBi (Attention with Linear Biases) instead
- Training: Optimized for commercial use with clear licensing
ALiBi’s position-independent approach allows MPT models to extrapolate to sequence lengths far beyond their training regime, making them exceptionally versatile for long-document tasks.
6. Dolly 2.0 (Databricks)
Dolly 2.0 is built on the EleutherAI Pythia model family and fine-tuned on instruction-following data.
Key Parameters:
- Base Model: Pythia-12B (12 billion parameters)
- Training Data: 15,000 human-generated instruction-response pairs
- Architecture: Standard transformer decoder
- Key Innovation: High-quality, human-curated instruction dataset
- License: Fully open for commercial use
Dolly’s significance lies not in architectural innovation but in demonstrating that relatively small, high-quality instruction datasets can create capable assistants.
7. OpenLLaMA (OpenLM Research)
An open reproduction of Meta’s LLaMA, trained on the RedPajama dataset.
Key Parameters:
- Sizes: 3B, 7B, 13B
- Training Tokens: 1 trillion
- Dataset: RedPajama (CommonCrawl, C4, GitHub, Wikipedia, books, ArXiv, StackExchange)
- Architecture: Identical to LLaMA (decoder-only transformer)
- Distinct Feature: Fully transparent training process and data pipeline
OpenLLaMA proves that the academic community can reproduce closed-model performance with sufficient resources and coordination.
8. GPT-NeoX-20B (EleutherAI)
EleutherAI’s largest publicly released model, trained entirely on open infrastructure.
Key Parameters:
- Parameters: 20 billion
- Context Length: 2,048 tokens
- Architecture: GPT-3-style with rotary embeddings
- Training Data: The Pile (825GB diverse text corpus)
- Layers: 44 transformer layers
- Hidden Dimension: 6,144
GPT-NeoX introduced several training optimizations including ZeRO optimization and pipeline parallelism, making large-scale training more accessible.
9. BLOOM (BigScience)
A multilingual model trained collaboratively by over 1,000 researchers from 70+ countries.
Key Parameters:
- Parameters: 176 billion
- Languages: 46 natural languages and 13 programming languages
- Architecture: Decoder-only with ALiBi positional encodings
- Training Data: 1.6TB ROOTS corpus
- Unique Feature: Explicit multilingual balanced training
BLOOM’s ALiBi implementation eliminates traditional positional embeddings, saving parameters and enabling length extrapolation. The model also uses embedding layernorm for training stability.
10. Vicuna (LMSYS)
Fine-tuned from LLaMA using user-shared conversations from ShareGPT.
Key Parameters:
- Base Model: LLaMA 7B or 13B
- Training Data: ~70,000 user-shared ChatGPT conversations
- Cost: Training cost approximately $300 using cloud compute
- Innovation: Demonstrates effective fine-tuning on conversational data
- Multi-turn Capability: Optimized for dialogue contexts
Vicuna pioneered the use of real user conversations for alignment, showing that publicly available interaction data could approach proprietary chatbot quality.
Chinese Open-Source AI Models
11. ChatGLM (Zhipu AI & Tsinghua University)
ChatGLM represents one of China’s most significant open-source contributions, with ChatGLM-6B and ChatGLM2-6B iterations.
Key Parameters:
- Parameters: 6.2 billion
- Architecture: General Language Model (GLM) with bidirectional attention
- Context Length: 32,768 tokens (ChatGLM2)
- Unique Design: Combines autoregressive and autoencoding objectives
- Multi-Query Attention: Reduces KV cache memory
- FlashAttention Integration: Enhances efficiency
ChatGLM’s innovative architecture uses a bidirectional encoder for prefix tokens and autoregressive generation for continuation, blending BERT-style and GPT-style paradigms. The model also implements Multi-Query Attention where all attention heads share a single set of keys and values.
12. Baichuan (Baichuan Intelligence)
Founded by former Sogou CEO Wang Xiaochuan, Baichuan released several competitive models.
Key Parameters:
- Versions: Baichuan-7B, Baichuan-13B, Baichuan2-7B, Baichuan2-13B
- Context Length: 4,096 tokens
- Training Data: 1.4 trillion high-quality tokens
- Tokenizer: Optimized for Chinese (125,696 vocabulary)
- Unique Feature: NormHead replacing traditional projection head
- Architecture: Standard transformer with xFormers optimization
NormHead normalizes the output logits, improving training stability and performance. Baichuan models also employ Rotary Position Embeddings (RoPE) for better positional awareness.
13. Qwen (Alibaba Cloud)
Alibaba’s Qwen (Tongyi Qianwen) series includes models from 1.8B to 72B parameters.
Key Parameters:
- Sizes: 1.8B, 7B, 14B, 72B
- Context Length: Up to 32,768 tokens (extended versions reach 1M tokens)
- Training Data: 3+ trillion tokens
- Architecture: Transformer with SwiGLU activation
- Grouped-Query Attention: Implemented in larger models
- Unique Feature: Extensive instruction-following fine-tuning
Qwen-72B uses a tiered attention structure with 64 attention heads but only 8 key-value heads (8:1 ratio GQA), dramatically reducing memory requirements while maintaining quality.
14. InternLM (Shanghai AI Laboratory)
Developed by Shanghai AI Lab in collaboration with several universities, InternLM emphasizes both capability and safety.
Key Parameters:
- Versions: InternLM-7B, InternLM-20B
- Context Length: 8,192 tokens (extendable to 200k+ with RoPE scaling)
- Training Phases: Three-stage training (pre-training, SFT, RLHF)
- Unique Feature: Cool-down training phase
- Architecture: Decoder-only with GQA
InternLM’s cool-down phase involves training on high-quality data with reduced learning rate in final stages, significantly improving model behavior. The model also implements dynamic NTK-aware interpolation for context extension.
15. Aquila (Beijing Academy of Artificial Intelligence)
The Aquila series from BAAI offers both English and bilingual models.
Key Parameters:
- Sizes: Aquila-7B, Aquila-33B
- Context Length: 2,048 tokens
- Architecture: Decoder-only with RoPE
- Training Data: 1.4 trillion tokens (bilingual corpus)
- Unique Feature: Bilingual co-training approach
- Tokenizer: 100,008 vocabulary optimized for Chinese-English
Aquila implements a balanced bilingual training strategy rather than primarily training on one language then adapting, resulting in more natural code-switching and translation capabilities.
16. MOSS (Fudan University)
China’s first conversational large language model released for academic research.
Key Parameters:
- Parameters: 16 billion
- Base Model: CodeGen architecture
- Context Length: 2,048 tokens
- Training Approach: Multi-stage including conversation fine-tuning
- Plugin System: Integrated tool-calling capabilities
- Unique Feature: One of the first Chinese models with plugin architecture
MOSS pioneered tool integration in Chinese LLMs, enabling web search, equation solving, text-to-image generation, and other capabilities through a plugin framework.
17. TigerBot (TigerResearch)
Focused on diverse task capabilities across Chinese applications.
Key Parameters:
- Sizes: 7B, 13B, 70B, 180B
- Training Data: 500B+ tokens (including 100GB+ instruction data)
- Context Length: 4,096 tokens
- Architecture: Standard transformer with optimizations
- Unique Feature: Extensive multitask fine-tuning
- Domain Coverage: Finance, law, encyclopedia, literary translation
TigerBot employs task-specific adapters and has been fine-tuned on over 10 million instruction samples across diverse domains, making it highly versatile.
18. Yuan 2.0 (Inspur)
Developed by Chinese computing giant Inspur, Yuan focuses on multimodal capabilities.
Key Parameters:
- Sizes: Yuan-2B, Yuan-51B, Yuan-102B
- Context Length: 8,192 tokens
- Architecture: Localized filtering attention mechanism
- Training Data: 2 trillion tokens
- Unique Feature: Attention router for efficient computation
- Multimodal: Includes vision-language variants
Yuan’s localized filtering attention selectively focuses on relevant tokens, reducing computational complexity from O(n²) to nearly O(n) for long sequences through learned importance scoring.
19. Skywork (Kunlun Tech)
A bilingual foundation model emphasizing data quality over quantity.
Key Parameters:
- Parameters: 13 billion
- Training Data: 3.2 trillion tokens (highly filtered)
- Context Length: 4,096 tokens
- Architecture: Standard transformer with optimized training schedule
- Unique Feature: Two-stage pre-training with different data mixtures
- Training Innovation: Dynamic batch sizing based on loss convergence
Skywork implements sophisticated data curriculum learning, gradually introducing more complex and diverse data as training progresses, which improves final model quality.
20. BlueLM (vivo)
Developed by smartphone manufacturer vivo for on-device and cloud deployment.
Key Parameters:
- Sizes: 7B, 13B
- Context Length: 32,768 tokens
- Architecture: Transformer with efficient attention mechanisms
- Training Data: 2.6 trillion tokens
- Unique Feature: Optimized for mobile deployment
- Quantization: Native support for INT4 and INT8 quantization
BlueLM emphasizes inference efficiency, implementing custom kernels for mobile CPUs and GPUs. The model architecture includes sparse attention patterns that reduce computation by up to 40% on device while maintaining quality.
Comparative Analysis
Parameter Efficiency Trends
The trend in open-source models has shifted from raw parameter count to efficiency. Models like Mistral 7B and ChatGLM-6B demonstrate that architectural innovations—sliding window attention, multi-query attention, and efficient activations—can match or exceed larger models’ performance.
Attention Mechanisms Evolution
Multiple attention innovations appear across these models:
- Multi-Query Attention (MQA): Shares key-value pairs across heads (Falcon, ChatGLM)
- Grouped-Query Attention (GQA): Balances MQA and standard attention (LLaMA 2, Qwen)
- Sliding Window Attention: Reduces memory while maintaining context (Mistral)
- ALiBi: Position-independent attention biasing (MPT, BLOOM)
Context Length Progression
Context length capabilities have exploded from 2,048 tokens (early 2023) to over 1 million tokens (Qwen-LM), driven by RoPE scaling, attention optimizations, and architectural innovations.
Regional Approaches
American models tend to emphasize:
- Broader multilingual capabilities from inception
- Transparent training processes and dataset documentation
- Community-driven development and collaborative governance
Chinese models tend to emphasize:
- Strong bilingual (Chinese-English) performance
- Domain-specific fine-tuning for practical applications
- Mobile and edge deployment optimization
- Rapid iteration and model family expansion
The Open-Source Advantage
These 20 models collectively demonstrate open-source AI’s transformative impact:
- Democratized Access: Researchers and developers worldwide can build sophisticated AI applications without massive computational resources.
- Rapid Innovation: Open architectures enable quick experimentation with new techniques, accelerating the entire field.
- Transparency: Open models allow inspection for biases, capabilities, and limitations—critical for responsible AI development.
- Customization: Organizations can fine-tune models for specific domains, languages, or use cases.
- Cost Reduction: Open-source models eliminate per-token API costs, making AI economically viable for more applications.
Future Directions
The open-source AI landscape continues evolving rapidly. Emerging trends include:
- Mixture of Experts (MoE): Activating only relevant parameters per task
- Extended Context: Multi-million token context windows
- Multimodal Integration: Seamless text, vision, audio processing
- Efficient Fine-tuning: LoRA, QLoRA, and other parameter-efficient methods
- On-device Deployment: Aggressive quantization and distillation for mobile devices
The competition and collaboration between American and Chinese open-source efforts create a dynamic ecosystem driving global AI advancement. As these models improve, the gap between open-source and proprietary systems continues narrowing, promising a future where state-of-the-art AI is accessible to all.




Be First to Comment