
Introduction
As artificial intelligence continues to reshape how we interact with technology, understanding the fundamental building blocks of AI language models becomes increasingly important. Three core concepts—tokens, words, and parameters—form the foundation of how modern AI systems like GPT-4, Claude, and other large language models process and generate text. This comprehensive guide explores these concepts in depth, revealing how they work together to enable AI systems to understand and generate human-like text.
Part 1: AI Tokens – The Currency of Language Models
What Are Tokens?
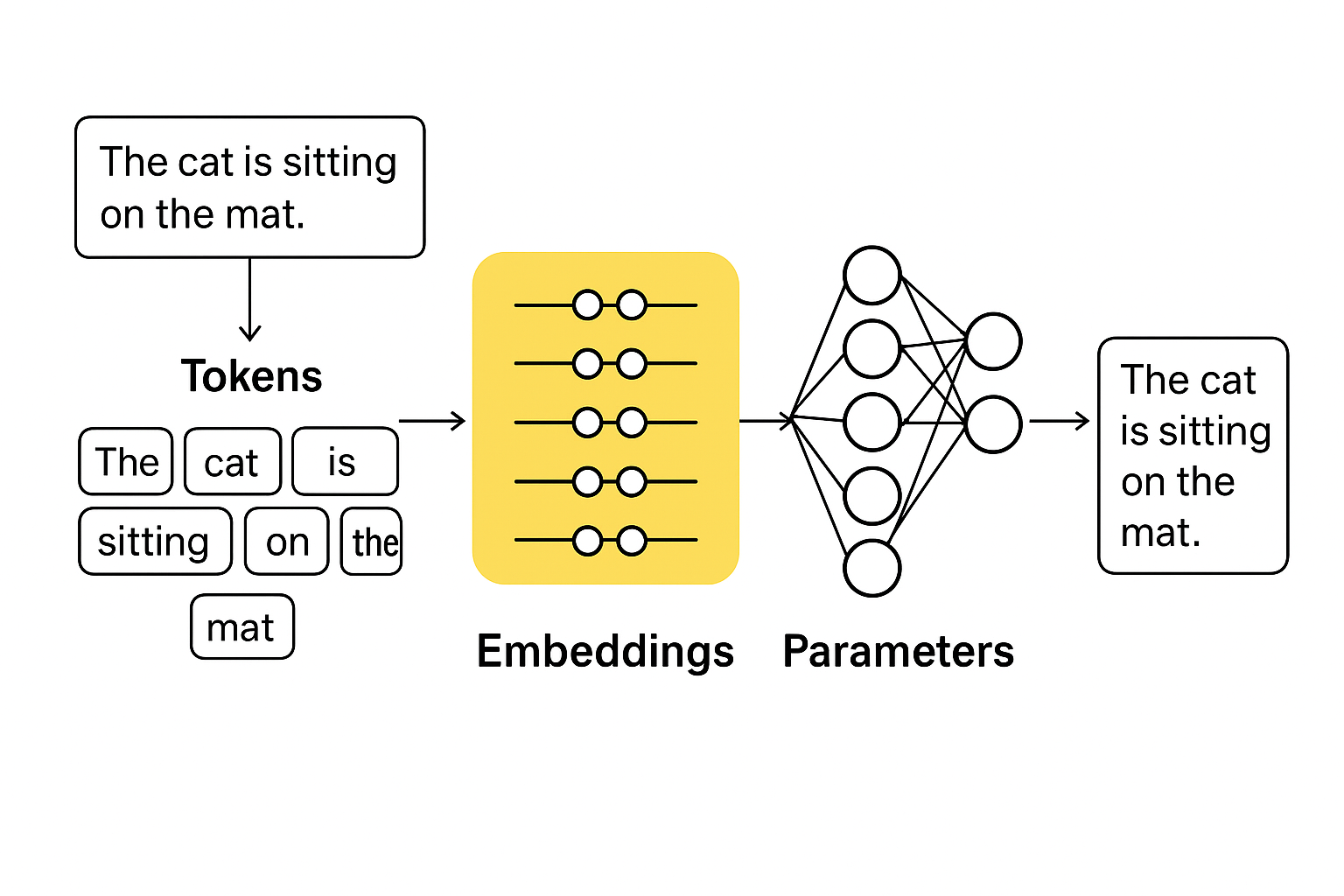
Tokens are the fundamental units that AI language models use to process text. Think of tokens as the “atoms” of language processing—they’re the smallest pieces into which text is broken down before an AI model can work with it. However, tokens are not always equivalent to words, which often surprises newcomers to AI technology.
How Tokenization Works
When you input text into an AI system, the first step is tokenization—the process of breaking down your input into tokens. This process follows specific rules that have been learned during the model’s training phase. Different AI models may use different tokenization schemes, but the general principles remain consistent.
A token can be:
- A complete word (like “cat” or “running”)
- Part of a word (like “un” from “unhappy”)
- A single character (especially for unusual characters or symbols)
- Punctuation marks
- Spaces or special characters
Examples of Tokenization
To illustrate how tokenization works in practice, consider these examples:
Simple sentence: “The cat sat on the mat”
- This might be tokenized as: [“The”, ” cat”, ” sat”, ” on”, ” the”, ” mat”]
- Token count: 6 tokens
Complex word: “understanding”
- This might be tokenized as: [“under”, “standing”] or [“understand”, “ing”]
- Token count: 2 tokens
Technical term: “electroencephalography”
- This might be tokenized as: [“elect”, “ro”, “en”, “cep”, “hal”, “ography”]
- Token count: 6 tokens
Mixed content: “She’s working on AI-powered apps!”
- This might be tokenized as: [“She”, “‘s”, ” working”, ” on”, ” AI”, “-“, “powered”, ” apps”, “!”]
- Token count: 9 tokens
Why Tokenization Matters
Understanding tokenization is crucial for several practical reasons:
Cost Implications: Many AI services charge based on token usage rather than word count. Since a single word might be broken into multiple tokens, your actual costs could be higher than expected if you’re only counting words.
Context Window Limitations: AI models have maximum context lengths measured in tokens, not words. For instance, a model with a 100,000-token context window might handle anywhere from 70,000 to 85,000 words, depending on the complexity of the text.
Performance Considerations: Longer token sequences require more computational resources and can affect response times. Understanding token usage helps optimize interactions with AI systems.
Multilingual Differences: Different languages tokenize differently. English typically has favorable tokenization ratios, while languages like Chinese, Japanese, or languages with complex morphology may use more tokens per word.
Subword Tokenization Methods
Modern AI models use sophisticated subword tokenization algorithms. The most common approaches include:
Byte Pair Encoding (BPE): This method starts with individual characters and iteratively merges the most frequent pairs. It’s used by GPT models and creates a vocabulary of subword units that balance between character-level and word-level representation.
WordPiece: Developed by Google, this method is similar to BPE but uses a different scoring system based on likelihood maximization. It’s used in BERT and similar models.
SentencePiece: This method treats the input as a raw stream of Unicode characters and can work directly from raw text without pre-tokenization, making it language-agnostic.
Unigram Language Model: This approach starts with a large vocabulary and progressively removes tokens, keeping those that minimize the loss on the training data.
Token Efficiency Tips
To make the most of your token budget when working with AI systems:
- Be concise but clear in your prompts
- Avoid unnecessary repetition
- Use standard vocabulary when possible (uncommon words often require more tokens)
- Be aware that formatting characters (spaces, line breaks, special symbols) also consume tokens
- Consider that longer, more complex words typically use more tokens than shorter, common words
Part 2: Words in Natural Language Processing
The Relationship Between Words and Tokens
While tokens are the technical unit AI models use, words remain the natural unit of human communication. The relationship between words and tokens is not one-to-one, which creates an interesting dynamic in AI language processing.
On average, in English text:
- Common words are typically 1 token
- Average words are about 1.3-1.5 tokens
- Complex or technical words can be 2-4 tokens or more
- Very long or specialized terms might exceed 5 tokens
Word-Level Understanding in AI
Despite processing text as tokens, AI models develop sophisticated word-level understanding through their training. This includes:
Semantic Understanding: Models learn what words mean based on their context across millions of examples. The word “bank” might mean a financial institution or a river’s edge, and the model learns to distinguish based on surrounding context.
Syntactic Relationships: AI systems learn how words relate to each other grammatically, understanding subjects, verbs, objects, and modifiers without explicit grammatical rules being programmed.
Morphological Awareness: Through tokenization and training, models develop an understanding of word roots, prefixes, and suffixes, enabling them to handle new or rare word forms.
Vocabulary Size and Coverage
Language models work with vocabularies typically ranging from 30,000 to over 100,000 tokens. This vocabulary size represents a strategic balance:
Smaller vocabularies mean:
- More subword splitting
- Longer token sequences
- Better handling of rare words through composition
- More efficient model architecture
Larger vocabularies mean:
- Fewer splits for common words
- Shorter token sequences for the same text
- More direct representation of frequent words
- Larger model size and potentially slower processing
Context and Word Meaning
One of the remarkable capabilities of modern AI language models is understanding context-dependent word meaning. Unlike traditional dictionary definitions, these models understand that:
- Words can have multiple meanings based on context
- The same word can function as different parts of speech
- Subtle connotations and implications matter
- Cultural and domain-specific usage varies
- Figurative language requires interpretation beyond literal meaning
Word Frequency and Model Behavior
AI models are heavily influenced by word frequency in their training data. This affects how they:
Generate text: More frequent words and phrases appear more readily in outputs Understand queries: Common phrasings are better understood than unusual constructions Handle rare terms: Infrequent words may be less reliably interpreted or used Exhibit biases: Frequent associations in training data can create unexpected biases
Part 3: AI Parameters – The Brain of the Model
What Are Parameters?
Parameters are the learned values that make up an AI model’s “knowledge” and capabilities. If tokens are how the model processes information and words are what it communicates, parameters are the accumulated wisdom that enables the model to understand and generate language.
In technical terms, parameters are numerical weights in the neural network that determine how input signals are transformed into outputs. Every connection between neurons in the network has associated parameters that are adjusted during training to minimize errors and improve performance.
The Scale of Modern AI Models
The number of parameters in an AI model is often used as a rough proxy for its capability and sophistication. The scale has grown dramatically over recent years:
Early Language Models (2017-2018):
- BERT Base: 110 million parameters
- GPT-1: 117 million parameters
Second Generation (2019-2020):
- BERT Large: 340 million parameters
- GPT-2: 1.5 billion parameters
- T5: 11 billion parameters
Modern Large Language Models (2021-2024):
- GPT-3: 175 billion parameters
- Various GPT-4 estimates: hundreds of billions to over 1 trillion parameters
- Claude models: specific parameter counts not publicly disclosed but in the hundreds of billions
- LLaMA 2: 7 billion to 70 billion parameters (various sizes)
- Gemini Ultra: estimated 1.5+ trillion parameters
What Parameters Actually Do
Parameters in a language model serve multiple interconnected functions:
Pattern Recognition: Parameters encode patterns learned from training data, from simple patterns like letter combinations to complex patterns like argumentation structures or narrative arcs.
Feature Extraction: Early layers of parameters learn to identify basic features (like character combinations or word parts), while deeper layers recognize increasingly abstract concepts (like topics, themes, or logical relationships).
Contextual Understanding: Parameters enable the model to maintain and use context, understanding how words relate to each other across sentences and paragraphs.
Knowledge Storage: While not a database in the traditional sense, parameters implicitly store factual knowledge, conceptual relationships, and procedural understanding encountered during training.
Style and Tone: Parameters capture stylistic patterns, enabling the model to generate text in different tones, formats, and genres.
More Parameters = Better Performance?
The relationship between parameter count and performance is nuanced. Generally, more parameters can enable:
- Better understanding of complex queries
- More sophisticated reasoning capabilities
- Broader knowledge coverage
- Improved handling of edge cases and rare scenarios
- Better maintenance of context over longer conversations
However, more parameters also mean:
- Higher computational costs for training and inference
- Greater memory requirements
- Longer processing times
- Increased potential for overfitting to training data
- More challenging deployment and scaling
Recent research has shown that parameter count alone doesn’t determine quality. Factors like training data quality, architecture design, training methodology, and alignment procedures are equally or more important.
Parameter Efficiency and Optimization
Modern AI research focuses heavily on parameter efficiency—getting the most capability from the fewest parameters. Techniques include:
Sparse Models: Not all parameters are active for every input, allowing models to be effectively larger without proportional computational costs.
Mixture of Experts (MoE): Different specialized sub-networks (experts) handle different types of inputs, with routing mechanisms determining which experts to activate.
Quantization: Reducing the numerical precision of parameters (from 32-bit to 16-bit or even 8-bit) can dramatically reduce model size with minimal quality loss.
Distillation: Training smaller “student” models to replicate the behavior of larger “teacher” models, capturing much of the capability in fewer parameters.
LoRA (Low-Rank Adaptation): Fine-tuning only small additional parameter sets rather than the entire model, making customization much more efficient.
How Parameters Are Learned
Parameters don’t start out knowing anything—they begin with random values and are refined through training. The training process involves:
Forward Pass: Input text is processed through the network, with each parameter contributing to transformations along the way.
Loss Calculation: The model’s output is compared to the desired output, producing an error measure.
Backpropagation: The error is propagated backward through the network, calculating how much each parameter contributed to the error.
Gradient Descent: Parameters are adjusted slightly in directions that reduce the error.
Iteration: This process repeats billions of times across vast training datasets, gradually improving the parameters.
Training large language models requires enormous computational resources—often thousands of GPUs running for weeks or months, consuming megawatt-hours of electricity and costing millions of dollars.
Parameter Distribution Across the Model
Parameters aren’t uniformly distributed throughout a model. Different components have different parameter counts:
Embedding Layers: Convert tokens to numerical representations; parameter count equals vocabulary size × embedding dimension.
Attention Mechanisms: Enable the model to focus on relevant parts of the input; these are computationally intensive and parameter-rich.
Feed-Forward Networks: Transform representations at each layer; typically contain the majority of parameters in each transformer block.
Output Layers: Convert final representations back to token probabilities; size depends on vocabulary size.
Part 4: How Tokens, Words, and Parameters Work Together
The Processing Pipeline
When you interact with an AI language model, all three concepts work in concert:
Step 1: Tokenization Your input text is broken down into tokens using the model’s tokenization scheme. “I love artificial intelligence!” might become [“I”, ” love”, ” artificial”, ” intelligence”, “!”].
Step 2: Embedding Each token is converted into a high-dimensional numerical vector (embedding) using learned parameters. These embeddings capture semantic meaning and relationships.
Step 3: Contextual Processing The model’s parameters process these embeddings through multiple layers, with each layer’s parameters transforming the representations to capture increasingly abstract patterns and relationships.
Step 4: Attention Mechanisms Attention parameters determine which tokens should “pay attention” to which other tokens, enabling the model to understand relationships across the entire input sequence.
Step 5: Prediction The final layer’s parameters transform the processed representations into probability distributions over all possible next tokens.
Step 6: Generation For each position in the output, the model selects a token based on these probabilities, then feeds it back through the system to generate the next token.
Step 7: Detokenization The sequence of generated tokens is converted back into readable text for you.
Balancing Act: Context Windows and Token Limits
Every AI model has a maximum context window—the total number of tokens it can process at once. This includes both your input (the prompt) and the model’s output (the response). Understanding this balance is crucial for effective AI use.
A model with a 100,000-token context window might allocate them as:
- 80,000 tokens for your input (documents, conversation history, instructions)
- 20,000 tokens for the model’s response
If your input approaches the context limit, the available space for the model’s response shrinks proportionally.
Scaling Laws and Emergent Behaviors
Research has revealed fascinating relationships between model scale (parameters), training data size, and capabilities:
Predictable Improvements: Many capabilities improve smoothly as models grow larger, following mathematical “scaling laws.”
Emergent Abilities: Some capabilities appear suddenly at certain scale thresholds—models below a certain size can’t perform a task at all, while models above that threshold can perform it reasonably well.
Examples of emergence:
- Complex multi-step reasoning
- Following intricate instructions with multiple constraints
- Code generation in multiple programming languages
- Translation between language pairs not seen during training
- Creative problem-solving and analogy-making
Part 5: Practical Implications and Best Practices
Optimizing Your Prompts
Understanding tokens, words, and parameters enables more effective AI interactions:
Be Specific but Concise: Every word matters, but clarity trumps brevity. A slightly longer, clearer prompt often produces better results than an ambiguous short one.
Front-Load Important Information: Place your most critical instructions and context early in your prompt, as earlier tokens often have more influence on the model’s behavior.
Use Natural Language: Don’t try to “game” the tokenization by using weird formatting or abbreviations—models are trained on natural text and perform best with natural inputs.
Consider Token Costs: If you’re working with token-based pricing, be mindful of:
- Conversational history accumulating over time
- Uploaded documents consuming your token budget
- Repeated similar queries that could be batched
- Output length requirements balanced against your needs
Choosing the Right Model Size
Different tasks benefit from different model scales:
Smaller Models (7-13 billion parameters): Suitable for:
- Simple text classification
- Basic Q&A on straightforward topics
- Grammar correction
- Simple summarization
- Cost-sensitive applications requiring fast responses
Medium Models (30-70 billion parameters): Good for:
- General-purpose conversation
- Code generation for common languages
- Creative writing with moderate complexity
- Nuanced content moderation
- Most business applications
Large Models (100+ billion parameters): Best for:
- Complex reasoning tasks
- Advanced code generation and debugging
- Sophisticated creative writing
- Deep domain expertise requirements
- Multi-step problem-solving
- Subtle context understanding
Understanding Model Limitations
Despite impressive capabilities, token-based processing and parameter-based learning create inherent limitations:
Token Counting Isn’t Perfect: Models process text token-by-token and can lose track when asked to count words, characters, or perform precise manipulations of text structure.
Knowledge Cutoffs: Parameters store knowledge from training data, which has a cutoff date. Models can’t know about events after they were trained unless given that information.
No True Understanding: Despite appearing intelligent, models are pattern-matching systems without genuine comprehension, consciousness, or reasoning ability in the human sense.
Hallucinations: Models can generate plausible-sounding but incorrect information, especially when parameters don’t contain clear information about a topic.
Bias and Fairness: Parameters learn patterns from training data, including societal biases present in that data.
Future Directions
The field of AI language models continues to evolve rapidly:
More Efficient Architectures: Research focuses on achieving better performance with fewer parameters through improved architectures and training methods.
Multimodal Models: Combining language processing with vision, audio, and other modalities, requiring new approaches to tokenization and parameter organization.
Longer Context Windows: New techniques are extending context windows from thousands to millions of tokens, enabling entirely new use cases.
Adaptive Systems: Models that can adjust their parameters in real-time or specialize for individual users or domains.
Interpretability: Better understanding of what individual parameters and parameter groups actually do, improving our ability to control and improve models.
Conclusion
Tokens, words, and parameters form the foundational trinity of modern AI language models. Tokens serve as the processing currency, breaking language into manageable pieces. Words remain the natural interface for human communication, bridging our intent with the model’s token-based processing. Parameters encode the accumulated learning that enables understanding and generation.
Understanding these concepts transforms how we interact with AI systems. Instead of treating them as mysterious black boxes, we can appreciate the elegant engineering that enables machines to process and generate human language. We can craft better prompts, set realistic expectations, choose appropriate models for our needs, and troubleshoot issues when they arise.
As AI technology continues advancing, the specific details may change—new tokenization schemes may emerge, parameter counts may explode or efficiently shrink, and novel architectures may reshape the landscape. However, the fundamental principles of breaking language into processable units, learning patterns through adjustable parameters, and bridging the gap between human communication and machine processing will remain central to how we enable computers to work with human language.
Whether you’re a developer building AI-powered applications, a business professional leveraging AI tools, or simply a curious individual exploring this technology, understanding tokens, words, and parameters provides essential insight into one of the most transformative technologies of our time.





Be First to Comment